As I become more and more experienced with software development, I am very quickly discovering the limitations of the web. Having a desktop application that constantly needs to retrieve large amounts of data from the Internet is very, very slow. Sometimes, when network speeds are spotty, a simple interaction can take up to 30 seconds, which is definitely unacceptable for the end-user.
In order to solve this problem, I decided to restrict myself from looking at online solutions. I wanted to create a solution on my own.
First, I wanted to create a robust system for managing a database for an offline program. I looked into several different services, including Microsoft’s SQL Stack and a local MongoDB server. However, I found that most of these solutions were either too difficult to learn (I was used to setting up a MySQL server using cPanel and phpMyAdmin) or that they over-complicated the issue. Then, I came across SQLite, which happened to be exactly what I was looking for. It was a lightweight, speedy, local replica of MySQL. After spending about an hour reading the documentation, I realized that it was also super easy to setup. I began working on a library that would make working with a local SQLite database super easy.
Thus, SQLiteDatabaseManager was born. The project was meant to house functionality that would be used in all of my projects, and here are some of the key features that were packed into it:
- The ability to quickly create a local database
- The ability to quickly insert, delete, and update records knowing the table names, the fields, and the new values.
- The ability to have a small table-verification system that allowed the user to define table schemas and check the existing SQLite tables against these schemas for integrity verification.
- The ability to retry operations when they fail (the fail could be a result of a spontaneous locked file and a retry could fix everything)
SQLiteDatabaseManager worked well because all you needed to do was create a new instance of it, and everything worked out of the box. A new SQLite database was setup and managed by the library. After rigorous testing, this worked perfectly. Of course, the library still needs major work and many more features, but it does what it was intended to do at the moment. My offline data management system worked.
Now the problem was not just managing data offline, but getting it to sync to an online counter-part when a network was available (In a perfect world, all operations would be done on the local SQLite database (fast) and then they would be replicated on the duplicate remote MySQL database (slower) on a background thread). The idea was simple.
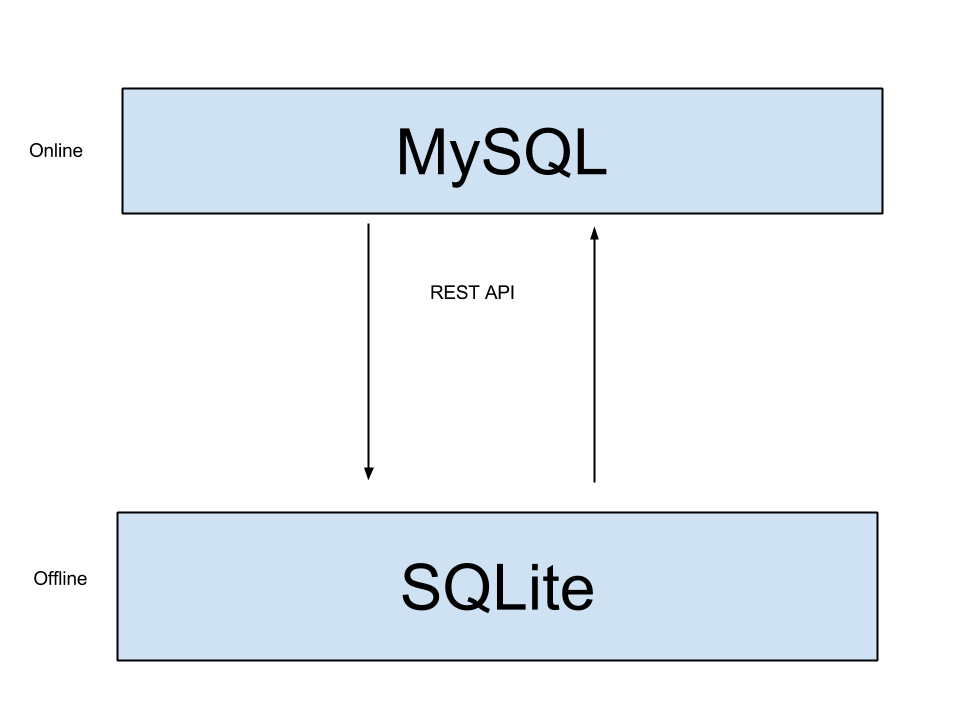 The SQLite database and the MySQL database would communicate with eachother via a simple REST API. The databases would be identical and the ID numbers created by the SQLite database would simply be moved to the MySQL database.
The SQLite database and the MySQL database would communicate with eachother via a simple REST API. The databases would be identical and the ID numbers created by the SQLite database would simply be moved to the MySQL database.
Creating the REST API for the remote MySQL portion of this project was rather simple. Relying on the methods of the LAMP stack, I used a set of PHP files that would receive GET, POST and DELETE requests so that data could be managed and manipulated fairly easily. Using PHP’s json_encode() function also proved very useful for creating readable responses.
Thus, with the creation of a working SQLite local database and a working and accessible remote MySQL database, I went ahead with the first iteration of implementing this idea. So far, I have run into a few problems.
An easily-solvable problem arose when thinking about how to handle many, many clients. Since there was only one remote MySQL database and many, many instances of the local SQLite database, it was a pain tracking when the local client’s changes actually had to be applied or if the remote version was actually newer. This problem was solved by creating a dateAltered field in both the remote and local databases that would contain the last date of modification of the data that it pertained to. Thus, the data with the latest dateAltered value was put permanently into the remote MySQL database.
But what about when there are many, many clients creating information. Surely, some of the client’s SQLite databases will assign ID numbers that coincide with other clients’ SQLite databases. Thus, when information is uploaded to the remote server, different pieces of information may have the same ID numbers. But since all data is modifiable, how is this detectable? This is a problem that I have not yet worked out a solution to since the first implementation of this design has a one-client one-server relationship. However, at the moment, I am hypothesizing that each data-entry contain a unique hash of its original state. Thus, database operations can be performed by referencing the ID of the element, but conflict-resolutions will use this hashed code. Thus, we will always be able to track if a certain piece of information has been modified from its original form or not. Thus, when uploading to the remote server, the server will manage some conflict resolutions and return the ID number of the object. The local clients will then reassign the ID number of the object to that ID number in order to match with the remote MySQL database.
I will continue to work on this project in the coming weeks, and I plan on making some detailed blog posts about it, so stay tuned! Eventually, I hope to have this process wrapped up in an easy-to-install and easy-to-implement library. We will see how that turns out.